
手元のAI運用で本当に欲しくなるのは、過去ログを丸ごと抱え込む巨大な知識庫より、次の判断に必要な断片だけを取りこぼさず渡してくれる軽い外部記憶です。今回の構成では Codex の hook を起点にしつつ、保存先は Obsidian で読める Markdown に寄せ、人間は必要な場面だけ中身を確認できる形にしています。
この運用の中心にあるのは、最初から長く残す知識を作ろうとしないことです。まずは超短期メモとして断片をその場で残し、そこからプロジェクトに関係する短期メモを拾い、さらに繰り返し使われるものだけを長く残す知識へ昇格させます。海馬になぞらえるなら、記録した瞬間に価値を決めるのではなく、あとで本当に使われたかどうかを見て残すか捨てるかを決める設計です。
記録の流れも雰囲気で回しているのではなく、hook ごとに役割をはっきり分けています。SessionStart では保管庫全体を読み返さず、直近の超短期メモと短期メモだけを少し読みます。UserPromptSubmit では、送信した内容をその場で外部メモに残します。Stop では、ひと区切りついた会話を短期メモとして追記します。つまり実態としては、「Obsidian を使いこなす運用」というより、「hooks が集めた記録を、あとで人間が読める Markdown で置いておく運用」と言ったほうが近いです。
焦点になるのは思想のきれいな説明ではなく、実装が本当にその思想を支えているかどうかです。hooks.json でどの Python スクリプトが呼ばれているのか、memory_hooks.py が超短期メモと短期メモをどう書き分けているのか、そして title 生成用 prompt まで混ざるような現行の粗さがどこに残っているのかまで含めて見ていくと、この外部記憶運用の強みと限界がかなりはっきり見えてきます。
なお、Codex の hooks はまだ試験的な実装で、今後仕様や使い方が変わる可能性があります。この記事で紹介している運用も固定完成版ではなく、実際に再現しながら手元の環境に合わせて調整していく前提で読むのが自然です。
海馬的Obsidian運用とは何か

人間の脳に備わっている海馬は超短期記憶領域として存在してますがcodexの海馬的な運用という言い方で伝えたいのは、Obsidian を中心に据えた整理術ではなく、「忘れやすい断片を先に超短期記憶領域に逃がして、あとから必要なものだけを残す」流れです。人が毎回きれいに整理してから保存する前提ではなく、まず保存し、その後の再利用で価値を判定するところに重心があります。
先に完璧な知識を作るのではなく、まず記録して、あとで使われたものだけを残すことです。
Obsidianを主役にしない設計思想
この仕組みで主役なのは Obsidian そのものではありません。主役は、会話の途中で出た判断材料を取りこぼさないための hook 側の自動記録です。Obsidian は、その記録を Markdown のまま置いておける保存場所であり、必要なら人間が開いて確認できる前面アプリとして使っています。
Obsidian を毎日がっつり開いて整理する人には、もっと別の運用もあります。ただ今回の流れは、GUI を常用しない人でも成立するように作られているのが特徴です。普段は Codex と会話しているだけで、記録は裏でたまり、必要なときだけ人間が覗けばいいという設計になっています。

Obsidian を触ること自体が目的ではなく、記録の置き場として信頼できる Markdown 保管庫を持つことが目的です。
実体はMarkdownでありObsidianのGUIは後から覗けるフロントである
ここでいう「Obsidianフォーマット」は、専用の特別な保存形式を意味しているわけではありません。実体は Markdown です。ただし frontmatter や note の置き場所が Obsidian で読みやすい形にそろっているので、あとで GUI から見ても破綻しません。
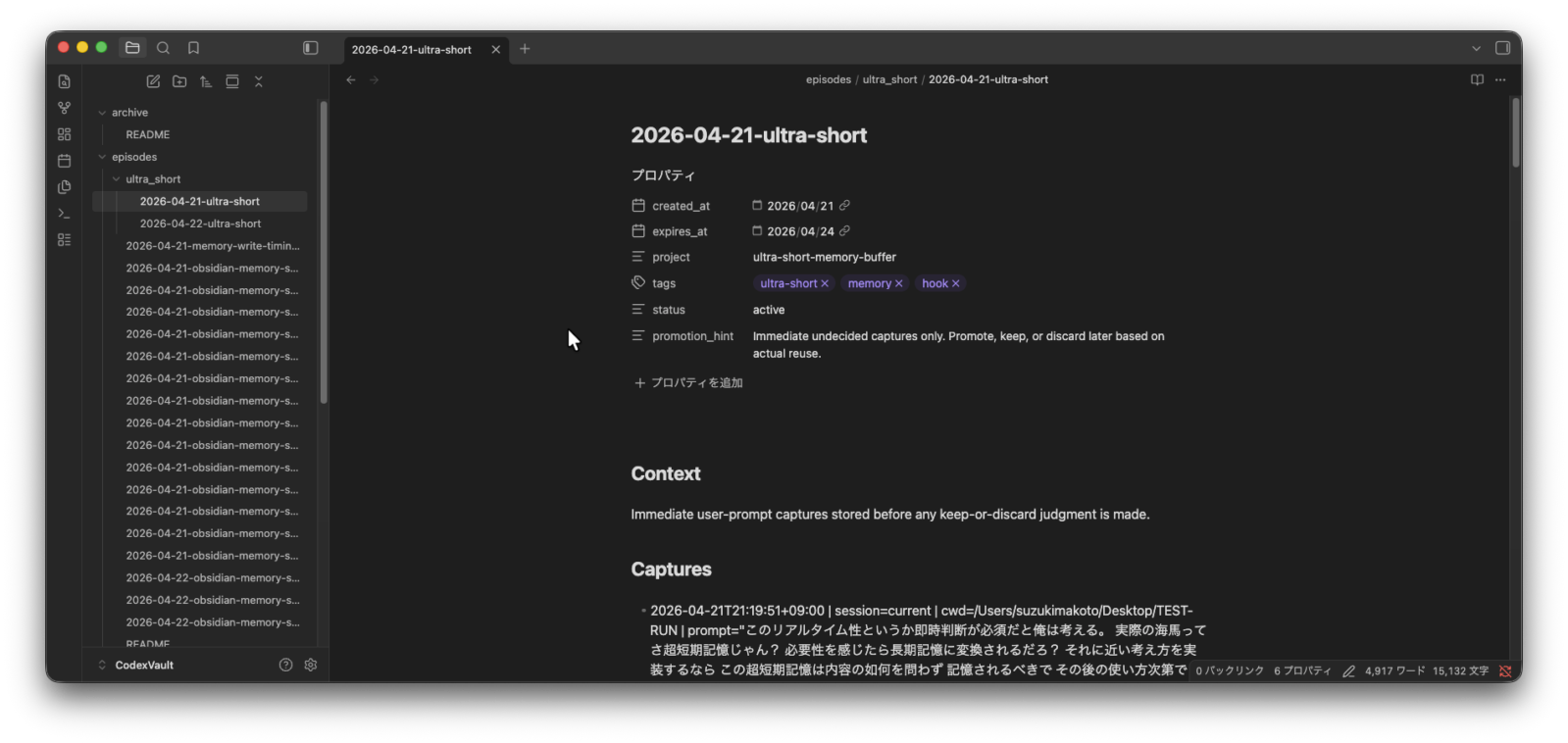
そのため、この運用を素直に言い換えるなら、「Obsidian 互換の Markdown で記録を持つ運用」です。保存されたファイルは単なる .md ですが、created_at や expires_at を frontmatter に持ち、episodes/ や knowledge/ に置かれるので、Obsidian 側でも整理しやすい構成になっています。
| 見え方 | 実体 |
|---|---|
| Obsidianで管理している記録 | frontmatter付きMarkdownファイル |
| GUIで読む運用 | 必要時だけObsidianのGUIで人間が開く確認手段 |
記憶レイヤーの構成

この運用は、すべての記録を同じ重さで扱わないように三層に分けています。超短期メモ、短中期メモ、長く残す知識を分けることで、保存した瞬間の雑味を許しつつ、あとでノイズだらけにならないようにしています。
- まずは未整理でも残す
- 次にプロジェクト寄りの短期メモへ寄せる
- 繰り返し使うものだけを長期知識へ昇格する
ultra_shortをグローバル混在inboxとして使う理由
超短期メモは、「まだ使うかどうかも決めていない断片」を置く場所です。ここで大事なのは、保存時点では価値判断をしないことです。あとで役に立つかもしれない、でも今はまだ断定できない。その段階のものを、とにかく取り逃がさないための受け皿になっています。
しかも ultra_short はプロジェクトごとに分けていません。そこを細かく分け始めると、保存するたびに「これはどこへ置くのか」という判断が増え、即時記録の利点が薄れます。まずは混ざった inbox として受けて、あとで必要に応じて project 側へ拾うほうが、実運用では軽いわけです。
整理の正しさより、今この瞬間の取りこぼしを防ぐことです。
episodesを短中期のproject寄りメモとして扱う理由
episodes は、超短期メモより一段だけ意味づけが進んだ記録です。会話の区切りや判断の切れ目で、「この話はこのプロジェクトに関係する」と見なせるものを、短中期のメモとして残します。ここでは単なる生ログではなく、短い要点にして残すので、あとで読み返しても何が起きたかを追いやすくなります。
この層を入れている理由は、knowledge に直接入れるにはまだ早いが、ultra_short のままでは雑すぎる記録が多いからです。特定プロジェクトの文脈で何度か参照されそうな話は、episodes に置いてしばらく持ち運べるようにしておくと、次の session での立ち上がりがかなり速くなります。
knowledgeに長く使うルールと決定だけを残す理由
knowledge は、何でも入れる棚ではありません。ここに入るのは、何度も使うルール、運用上の決定、プロジェクトの持続的な前提のように、あとから見ても価値が落ちにくい情報です。逆に言えば、ただの会話断片や一度きりの思いつきは、knowledge に直行させないほうが運用は健全になります。
長く残す層を軽く保つことは、読む側の負担を減らすことでもあります。起動直後に読むべきものが rules や project note に絞られていれば、必要な再読量も増えません。だからこそ episode-first が成立します。
hooksが担う実際の記録フロー

この運用の肝は、思想を会話で説明できることではなく、hook が実際に何をしているかがコードで追えることです。今回の構成では、hooks.json が入口になり、3つの hook event ごとに Python スクリプトが分かれています。
SessionStart、UserPromptSubmit、Stop の3つで、何を読むか、何を書くかを event ごとに分けます。
ultra_short、episodes、knowledge を分けて、保存直後の断片と長く残す知識を同じ棚に混ぜないようにします。
{
"SessionStart": "python3 ~/.codex/hooks/session_start.py",
"UserPromptSubmit": "python3 ~/.codex/hooks/user_prompt_submit.py",
"Stop": "python3 ~/.codex/hooks/stop.py"
}SessionStartで何を少量だけ再読するのか
新しい session が始まったとき、毎回 vault 全体をなめるようなことはしていません。SessionStart が見るのは、今の作業場所から推定した project に紐づく recent episode と、直近の ultra_short だけです。数も固定で、最近のものを少量だけ拾う設計になっています。
この絞り込みがあるから、再開時の読み込みが「とりあえず全部読んでおく」にならずに済みます。思い出しのための助走だけを最小限で入れ、必要になったらそこから rules や project note を追加で読む、という順番が守られます。
READ_LIMIT = 3
ULTRA_SHORT_READ_LIMIT = 4
ULTRA_SHORT_LOOKBACK_HOURS = 12ここで全部読まないのは手抜きではなく、起動時の負荷を増やさないための設計です。
UserPromptSubmitで何を即時外部化するのか
UserPromptSubmit は、この運用の中でいちばん即時性を担う hook です。ユーザーが送信した内容を受けた時点で、まず ultra_short に書き込みます。さらに project 判定と記録信号の強さを見て、episode 側にも残すべき内容なら短い要約を追記します。
ここで重要なのは、Stop まで待たないことです。session をまたいだり、途中で別の作業へ移ったりしても、送信した時点の論点が先に外へ逃げていれば、取りこぼしにくくなります。海馬的という言い方をするなら、まず痕跡を残してから、のちほど定着を判定する段です。
送信した prompt を、その時点で ultra_short に書き込みます。まだ価値判断はしません。
プロジェクトとの関係やキーワードの強さを見て、短い要約として episode に追記します。
capture_ultra_short_prompt(payload)
maybe_capture_user_prompt(payload)
additional_context = build_user_prompt_context(payload)Stopでどう会話ターンをepisode化するのか
Stop は、ひと区切りついた turn を短中期メモへまとめる役です。transcript から直近の user message を拾い、last assistant message と合わせて見ながら、project 判定と記録信号の強さを確認し、必要なら episode note に箇条書きで追記します。
この処理も、生ログの丸写しではありません。summarize_turn によって短い要点へ圧縮されるので、あとで読み返したときに「どんな会話をしていたか」がひと目で分かる形になります。つまり Stop は、会話を保存するというより、会話の意味を一段だけ圧縮して残す処理です。
last_user_message = last_user_message_from_transcript(...)
last_assistant_message = payload.get("last_assistant_message", "")
bullet = summarize_turn(last_user_message, last_assistant_message)
append_episode_bullet(note_path, bullet)新規セッションでの読み方

この仕組みは、書く流れだけでなく、次の session でどう読むかまで含めて成立しています。単に記録が残っているだけでは足りず、次に開いたときに何から読むべきかが決まっていないと、結局また全体を眺めることになってしまうからです。
二車線recallとしてのultra_shortとproject recent
新規 session の recall は二車線です。ひとつは、直近で発生した未整理の断片を拾う ultra_short。もうひとつは、今の project に関係する recent episode です。前者が「いま何が浮いているか」を拾い、後者が「このプロジェクトで直前に何が進んでいたか」を拾います。
この二車線にすることで、雑多な断片と project 固有の進行を無理に同じ場所で処理しなくて済みます。しかも両方とも少量読みなので、起動直後に情報が重くなりすぎません。思い出しの初速を上げるには、最初から完璧に理解するより、まず次の一手に必要な断片だけ思い出せれば十分です。
| 車線 | 読むもの |
|---|---|
| 車線1 | ultra_short の直近断片 |
| 車線2 | current project に関係する recent episode |
rulesとproject noteを必要時だけ読む運用
rules や project note は大事ですが、毎回必ず全部読む前提にはしていません。必要時だけ追加で読むからこそ、起動時の recall が軽く保てます。逆に、最初から長く残す知識を総なめする運用にすると、読む負荷が高くなり、再開のたびに重い儀式が発生します。
この順番は、運用の実用性に直結します。まず ultra_short と recent episode を読み、それで不足するときだけ rules や project note を開く。こうしておけば、記録量が増えても起動の重さが比例して膨らみにくくなります。
この運用が記事になる理由

この話が記事として面白いのは、単なるメモ術の紹介ではなく、実装と運用思想がかなり近い形で結びついているからです。よくある「あとで整理しましょう」という話ではなく、どの event で何を書き、どこに置き、どれだけ読むかまでコードで追えます。
Obsidian互換Markdown運用という言い方がしっくり来る背景
「Obsidian運用」と言うと、どうしても GUI の使い方や vault 整理術の話に寄りがちです。ただ今回の実態は、Codex の hook が書いた Markdown を Obsidian で読めるように整えているだけなので、「Obsidian互換 Markdown 運用」という言い方のほうがズレが少なくなります。
この言い方にすると、読者も誤解しにくくなります。Obsidian を毎日開いて整理する話ではなく、Markdown ベースの外部記憶を持ち、その保存形式が Obsidian と相性がよい、という説明になるからです。
hooks-firstの記憶実装として再現性があるポイント
この運用の強みは、人の気分に依存しにくい点です。記録の入り口を hook に置いているので、「今日はちゃんとメモする気分だったか」に左右されにくくなります。送信時、停止時、開始時という event に処理を固定しているため、最低限の記録が自動で積み上がります。
再現性があるというのは、毎回同じコードが同じ入り口で動くということでもあります。hooks.json から実行される 3 本の Python と、memory_hooks.py の共通処理を見れば、「どこで書いて、どこで読んでいるのか」が説明ではなく実装として確認できます。
公開したstarterから自分の環境で試せること
ここまで読んで「自分の Codex と Obsidian でも試したい」と思った人向けに、再現用の starter も公開しています。配布しているのは筆者の実運用 Vault そのものではなく、hook と最小の Vault 構成だけを切り出し、ほかの人の環境でも組み直しやすい形にした starter です。
再現用 starter は GitHub で公開しています。個人用の note 本文や実運用ログは含めず、hooks と最小構成だけを切り出した公開用パッケージです。
この starter のよいところは、手動で順番に組み立てる前に、GitHub の URL を渡したところから導入作業をかなりそのまま Codex へ任せられることです。まず GUI の Codex に repo の URL を渡して clone と open をやらせ、そのまま AGENTS.md、CODEX_SETUP.md、CODEX_INSTALLER.md を読ませます。そこまで読めば、その repo がどういう前提で作られていて、何をどこへ入れる想定なのかを Codex 側が把握できます。
そのうえで scripts/print_codex_installer_prompt.sh を Codex 自身に実行させれば、導入用の指示文がその場で出ます。読者はその内容に沿って bootstrap.sh と verify_install.sh まで進めればよく、細かい配線を人間が一つずつ覚える必要はありません。要するにこの starter は、README を人間が丹念に読むための repo というより、「repo を開いた Codex が installer モードに入りやすいようにしてある repo」です。
人間が最初に Codex へ渡す依頼も、かなり短くて済みます。README にある最短ルートは、次の一文です。
https://github.com/mlabo-org/codex-obsidian-memory-starter を clone して開き、この repo を installer として扱ってください。AGENTS.md、CODEX_SETUP.md、CODEX_INSTALLER.md、README.md を読み、scripts/print_codex_installer_prompt.sh を自分で実行して、bootstrap.sh と verify_install.sh まで完了してください。GitHub の codex-obsidian-memory-starter の URL を GUI の Codex に渡し、clone と open をそのままやらせたうえで、AGENTS.md、CODEX_SETUP.md、CODEX_INSTALLER.md を読ませます。
scripts/print_codex_installer_prompt.sh を Codex 自身に実行させ、その指示に従って bootstrap.sh と verify_install.sh までそのまま進めさせます。
もちろん、手で順に入れたい人向けの手順も starter 側に残っています。ただ、この記事の文脈で一番相性がいいのは、clone した repo を Codex に読ませて、その Codex に導入と検証までやらせる使い方です。調整が必要なのは主に Vault の保存先と project 判定ですが、そこも含めて Codex に読ませたほうがかなり楽です。
- clone するのは生の運用データではなく再現用 starter である
- 最短ルートは README を人間が追うことより Codex に repo を読ませることである
- 最初の確認ポイントは SessionStart の recall と ultra_short への即時書き込みである
現行実装の粗さと今後の改善余地
ここまでの流れは筋が通っていますが、現行実装が完成しているわけではありません。むしろ記事にするなら、粗さが残っている点も隠さず見せたほうが、運用の実感が伝わります。
この運用はもう動いていますが、まだ雑味やノイズを抱えたまま実戦で育てている段階です。
title生成用promptまで混ざるノイズ問題
いちばん分かりやすい粗さは、ultra_short に title 生成用の補助 prompt まで混ざってくることです。本来ここに欲しいのは、ユーザーが投げた判断前の断片ですが、実際にはタイトル作成用の内部寄り prompt も同じように並ぶことがあります。これは「とにかく先に拾う」設計の副作用です。
ただし、この粗さは完全な失敗とも言い切れません。まず拾うことを優先した結果として混入が起きているので、順番としては理解できます。今後は「何を即時保存するか」の条件を少しだけ絞り、必要な断片を落とさずにノイズだけを減らす方向が改善点になります。
skill文書とhook実装のレイアウト差分
運用文書ではきれいに整理されていても、hook 実装の実態はもう少し泥くさい部分があります。たとえば、文章としては layer の役割分担がすっきり見えていても、実際のコードは payload ログ、state ファイル、Markdown note の追記処理が別々に動いています。読む場所が複数に分かれているので、全体像をつかむには少し観察が要ります。
ここも記事にすると価値があります。設計資料だけだと美しく見えるものが、実装ではどこで分岐し、どこに痕跡が残るのかを追うことで、読者は「運用思想」と「実コード」の距離を具体的に理解できるからです。
長期知識への昇格基準がまだ発展途上である点
長く残す知識へいつ昇格させるかという判定は、まだ強い自動化にはなっていません。現状では、「何度も使われる」「今後も役立つ」といった基準はあるものの、完全に機械的な昇格条件が固まり切っているわけではありません。ここは今後さらに運用データを貯めながら調整していく段階です。
逆に言えば、この未完成さがあるからこそ、episode-first の設計が効いています。最初から完璧な昇格判定を要求すると仕組みが止まりやすいので、まずは episode まで確実に残し、knowledge への昇格は慎重にする。その順序が、現時点ではいちばん壊れにくい構成です。
まとめ

この運用を一言でまとめるなら、Codex の hooks を入口にして、超短期メモ、短期メモ、長期知識を段階的に分ける外部記憶の仕組みです。Obsidian は主役ではなく、記録を Markdown のまま置いておける保存庫であり、必要時だけ人間が覗くための前面アプリです。
読者にとって大事なのは、比喩だけで納得することではありません。SessionStart で何を少量だけ読むのか、UserPromptSubmit で何を即時保存するのか、Stop で何を episode 化するのかを追えば、この仕組みがかなり具体的なコードとファイル構成で動いていることが分かります。だからこそ、この運用は思想の話で終わらず、再現可能な実装仕様として説明する価値があります。
よくある質問











