
メモリ空間の課題と新しいアプローチ

ChatGPTの公式仕様におけるグローバルメモリの制約を克服するための新しいアプローチを提案します。 この方法により、プロジェクトやチャット単位で独立したメモリ空間を擬似的に作成し、効率的な情報管理を可能にします。
最初に出落ちするので申し訳ない。
記事を書いた時点ではなんとなく動作してたこの擬似メモリですがなんかいつのまにかセッションIDを参照できなくなっていますね。まぁ日々進化しているので仕様変更でしょうか・・・
擬似的にファイル名を作り出して識別できるように改造してみましたがなんかうまく動きませんね。
意図的にこの様なイレギュラーな使い方を潰されてる気がします笑
まぁ運営が想定しないハックは潰されることは多々あると思いますので気にしませんが
一点この実験過程で気がついたことがあります。
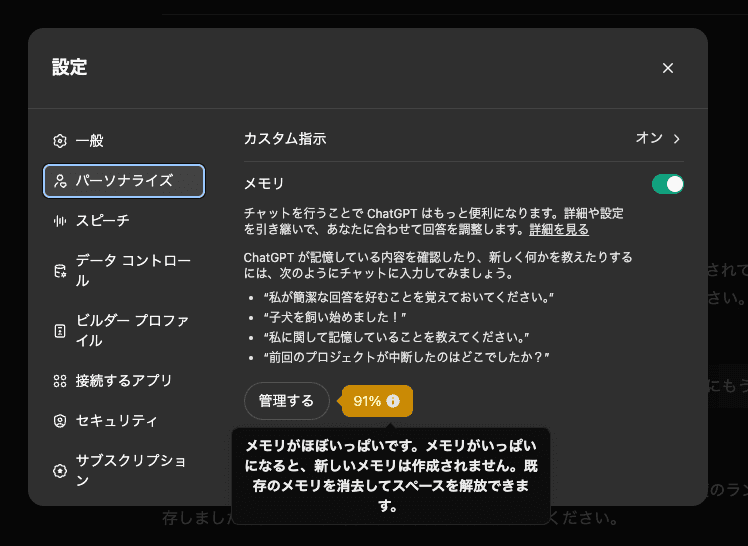
公式で言及されていないメモリ機能の上限ですがおおよそ14000文字であることが判明しました。
メモリの限界まで色々と書き込むと設定画面上にポップアップがでて91%などと上限をアピールしてきます。
以前ほぼ文字数制限無しだったのでここも仕様が変わったのでしょう。
以降の記事は斜めから構えればいろんなことが可能かもしれないという読み物として楽しんでください。
個別のローカルメモリー構想は現在のバージョンはかなり厳しいです><
なぜこのアプローチに至ったのか
ChatGPTは、基本的に「グローバルメモリ」を使用していますが、これにはいくつかの課題が存在します。 特に、複数のプロジェクトを並行して進める際に、それぞれのプロジェクトに固有の情報が混在するリスクがあります。 このような状態では、意図しない情報の交錯や誤った設定の適用が起こりやすくなり、作業効率を低下させる恐れがあります。
例えば、あるプロジェクトで特定の文体やメモリ設定を適用している場合でも、別のプロジェクトの設定が影響を及ぼしてしまうことがあります。 この問題を解決するために、「擬似的なチャット固有メモリ空間」を作成するというアプローチに至りました。
具体的には、「チャット固有の名称」を使って、各チャットに関連する情報を特定し、その情報だけを利用できるようにすることで、他のプロジェクトに影響を与えることなく、情報を独立させる方法です。 このアプローチにより、各プロジェクトやタスクに対して最適化されたメモリ管理を行うことができます。
この方法を採用することで、メモリがプロジェクト単位で分離され、誤った設定の適用や情報の交錯を防ぐことができ、作業効率や精度の向上が期待できます。
擬似的なチャット固有空間の作成方法

ChatGPTでは、チャット名を基に情報を分離し、メモリ内容を柔軟に管理する方法を提案します。 特定のプロジェクトやタスクごとに設定を最適化することで、効率的な作業環境を実現できます。
固有名称を活用したメモリ登録
ChatGPTでは、すべてのチャットに固有の名称を設定することが可能です。 この「固有名称」を利用して、情報を独立して管理します。 以下は具体的な手順と例です。
手順1: チャットの固有名称を設定する
新しいプロジェクトやタスクごとに、わかりやすい固有名称を設定します。 例えば、この記事の作成に使用しているチャットでは「チャット2024-12-31メモリ活用記事作成」という名称を使用しています。
この固有名称は次のような役割を果たします:
- 他のチャットと情報が混ざらないようにする。
- 記録したメモリを検索・参照しやすくする。
手順2: メモリの内容を固有名称に基づいて登録する
特定の固有名称に関連する情報だけを登録します。 例えば、「メモリ活用記事作成」というチャットでは以下の情報を登録しました:
- 記事のタイトル: ChatGPTのメモリ運用術|擬似的なチャット固有空間の作成法
- 記事の構成案: H1からH3に至る詳細な内容。
この登録によって、他のチャットでメモリ内容が参照されたり、意図しない影響を受けたりすることがなくなります。
手順3: 登録内容を確認・活用する
登録した内容を適宜確認し、必要に応じて更新します。 例えば、このチャットでは「句点の処理に関するルール」もメモリに追加しました。 これにより、同じルールが他のプロジェクトに影響を与えることなく適用されています。
実例: 「メモリ活用記事作成」の具体例
- チャット名: 「チャット2024-12-31メモリ活用記事作成」
- 登録されたメモリ:
- 記事構成案
- 記事タイトル
- 執筆ルール(句点処理など)
実験と考察

試行錯誤の過程
ChatGPTでのメモリ管理において、グローバルメモリとローカルメモリを区別するアプローチは、初期段階でいくつかの課題に直面しました。 例えば、以下のような問題がありました:
- 情報の混在:
- グローバルメモリに保存された内容が他のプロジェクトに影響を与えるケースが発生。
- 特定のチャット固有の情報を保持する方法がないため、意図しない情報の共有が起こりやすかった。
- 設定の曖昧さ:
- 各プロジェクトで異なる文体や方針を適用する際、統一された管理が困難。
- チャットごとに固有のメモリ設定を簡単に切り替える仕組みが必要だった。
これらの問題を解決するため、擬似的なチャット固有メモリ空間を導入しました。 試行錯誤を経て、次のような改善点を実現しました。
- 固有名称を活用: メモリをチャット単位で分けることで、情報の混在を防止。
- 登録と管理の明確化: 必要な情報だけをメモリに登録し、それ以外のプロジェクトと切り離して運用。
現在の運用方法と成果
現在の運用では、擬似的なチャット固有空間が想定通りに機能しています。 以下は具体的な成果です。
- メモリの独立性:
- 各チャットで固有の名称を利用し、情報の独立性を確保。
- 他のプロジェクトに影響を与えることなく、必要な情報を効率的に管理。
- 作業効率の向上:
- チャットごとに設定やルールを独立して適用できるため、迅速な対応が可能。
- 同じプロジェクト内でのチャット間の情報共有も明確に管理できる。
- 運用の安定性:
- これまでの実験結果では、意図しない情報の交錯が発生していない。
- 今後のプロジェクトでもこの手法を適用することで、さらなる効率化が期待される。
今後の応用可能性と課題

AIとの協働におけるメリット
擬似的なチャット固有空間を活用することで、AIとの協働がより効率的かつ柔軟になります。 以下は具体的なメリットです:
- プロジェクト単位での柔軟な運用:
- 各プロジェクトで必要な設定を独立して管理することで、AIのサポートを最適化。
- 例: 記事作成プロジェクトではSEO重視の文体を設定し、別プロジェクトではカジュアルなトーンを採用。
- 情報の交錯防止:
- チャットごとにメモリを分離することで、誤った情報が別プロジェクトに影響を与えるリスクを回避。
- これにより、AIが常に正確な情報を基に作業を進められる。
- 作業効率の向上:
- AIがプロジェクトごとに最適化されたメモリを利用するため、タスクへの対応速度と正確性が向上。
- 例: 一度設定した固有名称を参照するだけで、関連情報を迅速に呼び出せる。
今後の課題と改善案
擬似的なチャット固有空間には多くの利点がありますが、いくつかの課題も残されています。 以下は主な課題とその改善案です:
- 拡張性の課題:
- プロジェクトやチャットの数が増加すると、管理が複雑化する可能性があります。
- 改善案: メモリ管理の自動化ツールや、プロジェクト間での固有名称の重複を防ぐ仕組みを導入。
- 公式仕様への依存:
- この方法はChatGPTの公式仕様を前提としています。 仕様変更が行われた場合、運用に影響が出る可能性があります。
- 改善案: 定期的に仕様変更を確認し、運用方法を柔軟に調整する体制を構築。
- 予期せぬエラーのリスク:
- メモリ管理ミスや、意図しない内容が登録されるリスクがあります。
- 改善案: 登録内容を定期的にレビューし、不適切な情報を修正・削除する運用ルールを設ける。
- 長期運用での安定性検証:
- 長期間の運用では、現在見えていない問題が発生する可能性があります。
- 改善案: 実験データを蓄積し、長期的な影響を評価する仕組みを整える。
カスタムインストラクション(カスタム指示)

以下は、ChatGPTのカスタム指示機能を利用して擬似的なチャット固有メモリを活用するための具体例です。
あなたのChatGPTのカスタム指示の以下の欄にそのままコピペでOK。
質問: 回答を向上させるために、ChatGPTに知っておいてほしいことは何ですか?
複数のプロジェクトを作成する際、各プロジェクト内でのメモリはそのプロジェクト内でのみ使用され、他のプロジェクトやグローバルメモリには一切共有されないようにしてください。また、プロジェクト内に存在する個別チャット(例:記事ごとのセッション)のメモリも独立して管理されるべきです。各チャットのメモリは、そのチャット内でのみ利用され、同じプロジェクト内の他のチャットと共有されないようにしてください。プロジェクト全体およびチャットごとに完全に独立したメモリ空間を厳格に管理し、情報の漏洩や交錯を防止してください。
プロジェクト内のチャット内であらたにメモリ追加の必要性が出た場合は必ずそのチャット専用のメモリエリアに格納してください。
ユーザーはそのチャット専用のメモリ空間を「ローカル」「チャットメモリ」「固有メモリ」「現在の空間」「現在のエリア」など、もしくはそれに類似した表現を行いますので
メモリ格納先に不安がある場合は必ず確認をしてください。メモリに記載する内容の例

以下は、擬似メモリ空間を構築するために実際にメモリに登録する内容の具体例です。
ローカルメモリに登録された内容例
チャット2024-12-31メモリ活用記事作成
- 記事タイトル:
ChatGPTのメモリ運用術|擬似的なチャット固有空間の作成法- 記事構成案:
- H1: ChatGPTのメモリ運用術|擬似的なチャット固有空間の作成法
- H2: メモリ空間の課題と新しいアプローチ
- H2: 擬似的なチャット固有空間の作成方法
- H2: 実験と考察
- H2: 今後の応用可能性と課題
- 運用ルール:
- 句点の直後にスペースを挿入し、改行を行う。
- メモリの保存先はローカルメモリのみとし、グローバルには保存しない。
- フィードバック内容:
- グローバルメモリとローカルメモリを区別し、チャット単位での運用を強化する。
- 拡張性や仕様変更に対応するためのバックアップ案を検討する。
具体的な運用の流れ
- カスタム指示を設定:
- カスタムインストラクションで、グローバルとローカルメモリの区別を徹底する。
- メモリ登録:
- ローカルメモリに登録する内容をチャット単位で記載。
- チャットの固有名称を明示し、独立性を確保。
- メモリ運用:
- ローカルメモリの内容を適宜参照し、他チャットと情報が混ざらないよう運用する。
チャット毎に一意の識別名をつける方法(メモリに登録しておくプロンプト)

擬似的なチャット固有空間を運用するためには、各チャットに一意の識別名を設定することが重要です。この識別名によって、情報を他のチャットと区別し、独立したメモリ空間を確保できます。
一意の識別名を設定する具体的な方法
命名規則は独自に好きな形式で良いと思います。実際はChatGPT内部では名前で管理しているわけではなく
内部的にセッションIDを利用して識別しているらしいのでなんでも紐つけて参照可能だそうです。下記は例です。
手順1: チャット名に日付と内容を組み合わせる
識別名の一意性を保つため、以下の形式を推奨します:
チャット_YYYY-MM-DD_内容に基づくタイトル
- YYYY-MM-DD: チャット開始日を示します。これにより、同じ内容でも日付が異なる場合に識別可能になります。
- 内容に基づくタイトル: チャットの目的や内容を簡潔に記載します。
例:
- 記事作成用チャット:
チャット_2024-12-31_メモリ活用記事作成 - 技術相談用チャット:
チャット_2024-12-31_Node.js設定
手順2: 識別名をチャット開始時に設定する
新しいチャットを開始する際、識別名を以下のように設定します:
- チャットの目的を明確にします(例: 記事作成、技術相談、レビューなど)。
- 日付と目的に基づくタイトルを組み合わせて一意の識別名を作成します。
例:
- このチャットでは、
チャット_2024-12-31_メモリ活用記事作成を設定しました。
手順3: メモリ内容に識別名を記録する
設定した識別名をメモリ内容の冒頭に記録します。これにより、意図した識別名が正しく登録され、チャットごとの独立性を保証できます。
例:
チャット2024-12-31メモリ活用記事作成記事構成案: …
記事タイトル: ChatGPTのメモリ運用術|擬似的なチャット固有空間の作成法
識別名設定の効果
- 情報の混在防止:
- 各チャットの目的に基づいてメモリ内容を明確に区別できます。
- 他のプロジェクトやチャットに意図しない影響を与えません。
- 運用の効率化:
- 一意の識別名を基にメモリを検索・参照できるため、必要な情報に迅速にアクセスできます。
- 長期運用での管理性向上:
- 日付を含めた識別名により、過去のチャット内容を簡単に追跡可能。
グローバルメモリに登録した実際のプロンプト
必要に応じて、現在のメモリ空間とその内容を簡単に確認できる仕組みを維持する。.
チャットごとに一意の識別名を付ける。識別名にはプロジェクト名(またはID)、日時(YYYY-MM-DD)、および固有のタイトルや内容を含める形式とする。チャット開始時、自動的にチャット名を設定する命名規則をグローバルに適用しました。命名規則は以下の通りです:
1. プロジェクト名(またはID)を先頭に追加し、一意に識別可能にする。
2. プロジェクト内でチャットごとに一意なタイトルを付ける。
3. 日付(YYYY-MM-DD)を含める。
4. 自動生成した名前を提示し、ユーザーが必要に応じて修正可能なフローを適用。
5. ユーザーの希望により、チャット名の「内容未設定」部分は内容が確定次第、**完全自動化**で変更されるよう設定しました。以後、チャットの進行に伴い、内容に基づいて動的に名称を変更します。
構成例:
- `プロジェクト名_チャット_YYYY-MM-DD_内容`
- 例:
- `SEOブログ作成_チャット_2025-01-01_記事構成案`
- `技術検証_チャット_2025-01-02_レビュー進行`
プロジェクト外のチャットの命名規則を以下のように記録しました:
1. 「プロジェクト名」がないため、「未定義」や「プロジェクト外」という記述を含める。
2. チャット内での一意性を保つため、日付(YYYY-MM-DD)と内容を明記。
3. 内容未確定の場合は「内容未設定」と記載し、確定後に自動的に内容を反映。
例: `プロジェクト外_チャット_YYYY-MM-DD_内容`
ユーザーは、新規チャットを開いた際に記録が必要な場合、デフォルトで**ローカルエリア(チャット専用メモリ)**に優先的に記録されることを希望している。以前はChatGPTの判断でグローバルエリアに記録され、それがすべてのチャットに影響を与えていたため、定期的に手動削除を行っていた。今後もメンテナンスは継続するが、デフォルトで記憶がそのチャット限定になるよう設定することで利便性を高めたいと考えている。.
ユーザーの希望により、必要に応じて**どのメモリ空間に記録するか確認する**ことを徹底します。デフォルトはローカル(チャット専用メモリ)ですが、指示や状況に応じて確認を行い、適切なエリアに記録します。.
ユーザーは、メモリ空間を「グローバル」「プロジェクト」「チャット」という固有名称で擬似的に分類し、どのセッションでも共通で認識できるようにすることを希望しています。これにより、メモリ管理の透明性と一貫性を確保したいと考えています。.
まとめ

ChatGPTの公式仕様では、メモリは単なる「メモ」として機能するものであり、ユーザーとのやり取りの中で情報を一時的に保持するためのものです。 本来、プロジェクトやチャットごとに独立したメモリ空間をサポートする公式な機能は今の所は存在しません。 そのため、本記事で紹介した方法は、ChatGPTの仕様を最大限に活用し、擬似的にプロジェクト単位やチャット単位でメモリを分離する運用を工夫した結果です。
現時点での成果
筆者の環境では、この擬似的な運用方法に基づき、以下のような成果が得られています:
- 擬似的なメモリ独立性の確保:
- チャット固有の名称を活用し、情報の混在を防ぐことで、個別のプロジェクトやタスクに最適な設定が実現されています。
- 作業効率の向上:
- チャットごとに特化した情報を保持することで、効率的な作業が可能となっています。
- 運用の安定性:
- 現在の設定では、意図しない情報の共有や干渉が発生しておらず、安定して運用できています。
注意事項
ただし、この方法はChatGPTの公式な考え方や機能ではなく、あくまで擬似的に独立性を実現するための運用方法です。 メモリは本来、ユーザーの入力に基づく一時的な「メモ」であり、仕様の変更や長期運用では予期せぬ課題が発生する可能性があります。 そのため、以下の点に留意してください:
- 公式サポートがないこと:
この方法はChatGPTの仕様に基づく独自の工夫であり、公式のサポート対象外です。 - 運用環境の変化への備え:
ChatGPTの仕様が更新された場合、この方法が期待どおりに動作しなくなる可能性があります。
擬似的な運用方法ではありますが、現状では効率的かつ安定した成果を得ることができています。 今後もこの方法を検証しながら、さらに効果的な運用を模索していく予定です。 この記事が、読者の皆様がChatGPTを活用する際の参考となれば幸いです。
ChatGPTの擬似メモリ運用に関するよくある質問
ChatGPTにはチャットごとの独立したメモリ空間はありますか?
いいえ、ChatGPTの公式仕様ではチャットごとの独立したメモリ空間は存在せず、メモリは単なる「メモ」として一時的に情報を保持するものです。この記事で紹介した方法は、擬似的に独立性を実現するための工夫です。
擬似的なメモリ運用方法はどのように機能しますか?
チャットに一意の識別名を付け、その名前を基にメモリを分離して登録・活用する方法です。これにより、情報が他のプロジェクトやチャットに影響を与えることを防ぎます。
擬似的なメモリ運用のメリットは何ですか?
主なメリットは、情報の混在防止、作業効率の向上、そしてチャット単位でのカスタマイズ性の向上です。また、プロジェクトごとに特化した設定が適用できるため、より柔軟にAIを活用できます。
この方法は公式サポートされていますか?
いいえ、この方法はChatGPTの公式な考え方や機能ではありません。あくまでユーザーの工夫に基づく擬似的な運用方法であり、公式サポートの対象外です。
この運用方法の注意点は何ですか?
主な注意点は、公式仕様の変更によりこの方法が動作しなくなる可能性があること、そして長期運用での安定性を検証する必要があることです。また、情報管理を徹底するために定期的なメモリの見直しが推奨されます。












